자연어 처리(NLP, Natural Language Process)
목차
1. 자연어 처리(NLP, Natural Language Process)란?
자연어 처리(NLP, Natural Language Process): 머신 러닝을 사용하여 컴퓨터가 인간의 언어를 이해하고 소통하도록 돕는 인공 지능(AI)의 하위 분야이다.
자연어 처리(NLP) = 컴퓨터 언어학 + 통계 모델링 + 머신러닝, 딥러닝 => 컴퓨터 및 디지털 기기가 텍스트와 음성을 인식, 이해, 생성
2. NLP에 대한 접근 방식
자연어 처리(NLP) = 컴퓨터 언어학 + 통계 모델링 + 머신러닝, 딥러닝
컴퓨터 언어학(Computational Linguistics): 데이터 과학을 사용하여 언어와 음성을 분석한다.
여기에는 구문 분석과 의미 분석의 두 가지 주요 분석 유형이 포함된다.
- 구문 분석: 단어의 구문을 분석하고 미리 프로그래밍된 문법 규칙을 적용해 단어, 구 또는 문장의 의미를 결정한다.
- 의미 분석: 구문 분석을 사용해 단어에서 의미를 도출하고 문장 구조 내에서 그 의미를 해석한다.
단어 구문 분석은 두 가지 형식 중 하나를 사용할 수 있다.
- 종속성 구문 분석: 명사와 동사를 식별하는 등 단어 사이의 관계를 살펴본다.
- 구성 요소 구문 분석: 문장 또는 단어 문자열의 구문 구조를 뿌리부터 순서대로 표현한 구문 분석 트리(또는 구문 트리)를 구축한다.
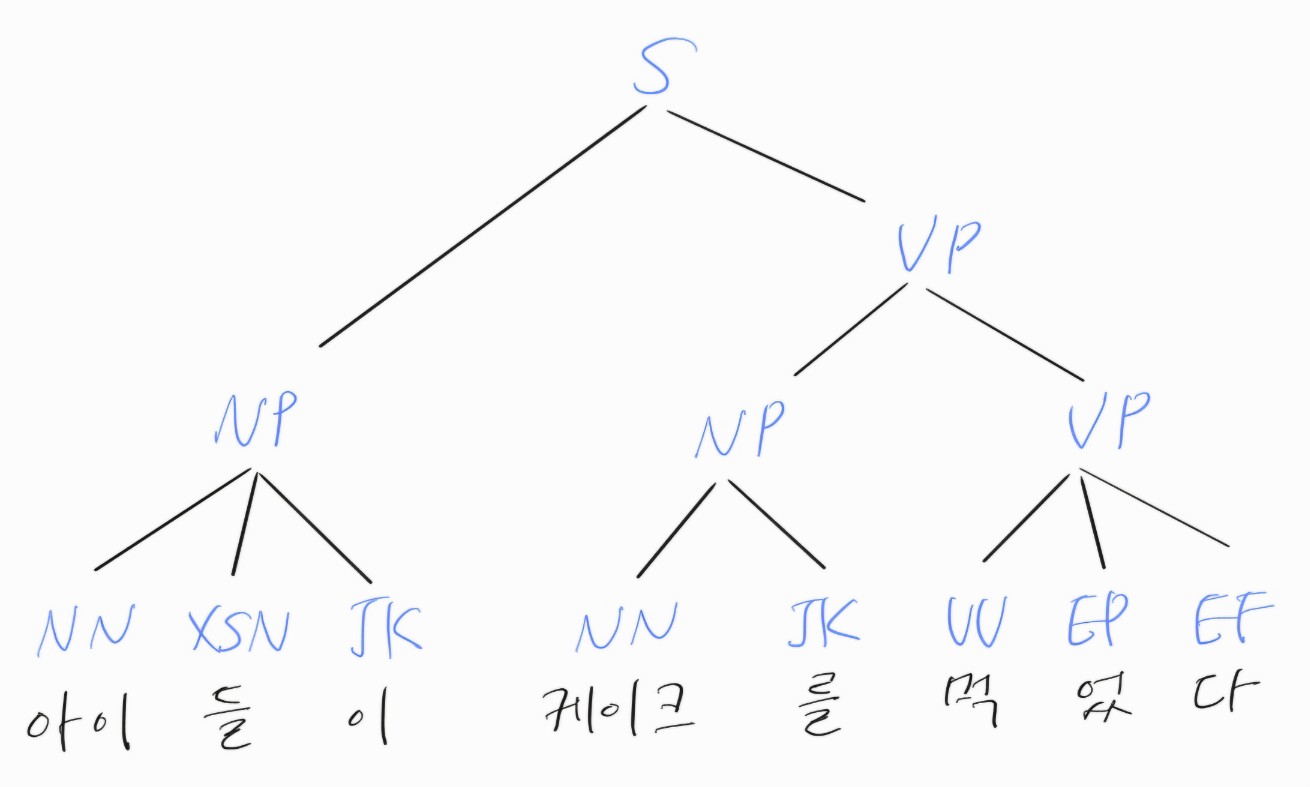
구문 분석 트리
NLP는 자기 지도 학습(SSL)을 사용하는 것이 유용하다.
왜냐하면 NLP는 AI 모델을 훈련시키기 위해 많은 양의 레이블이 지정된 데이터를 필요로 한다.
이러한 레이블이 지정된 데이터 세트의 경우 사람이 수동으로 레이블을 지정하는 프로세스인 주석이 필요하기 때문에 시간이 많이 걸려 충분한 데이터를 수집하는 것이 매우 어려울 수 있다.
그렇지만 자기 지도 학습(SSL)은 학습 데이터에 수동으로 라벨을 지정해야 하는 일부 또는 전체적인 업무를 대체하므로 시간과 비용 면에서 더 효율적일 수 있다.
NLP에 대한 세 가지 접근 방식은 다음과 같다.
2.1. 규칙 기반 NLP
규칙 기반 NLP: 사전 프로그래밍된 규칙이 필요한 단순한 if-then 의사 결정 트리이다.
초보적인 자연어 생성(NLG, Natural Language Generation) 기능을 통해 특정 프롬프트에 대한 응답으로만 답변을 제공한다. 규칙 기반 NLP에는 머신 러닝이나 AI 기능이 없기 때문에 이 기능은 매우 제한적이며 확장성이 떨어졌다.
2.2. 통계적 NLP
통계적 NLP: 텍스트 및 음성 데이터의 요소를 자동으로 추출, 분류 및 레이블을 지정한 다음 해당 요소의 가능한 각 의미에 통계적 우도(가능도)를 할당한다. 이는 머신 러닝을 기반으로 품사 태깅과 같은 정교한 언어학 분석을 가능하게 한다.
통계적 NLP는 회귀 또는 마르코프 모델을 비롯한 수학적(통계적) 방법을 사용하여 언어를 모델링할 수 있도록 단어 및 문법 규칙과 같은 언어 요소를 벡터 표현에 매핑하는 필수 기술을 도입했다. 이는 맞춤법 검사기 및 T9 문자(옛날 버튼식 전화기의 9개 버튼에 적힌 글자) 등 초기 NLP 개발에 정보를 제공했다.
2.3. 딥러닝 NLP
딥러닝 NLP: 최근에는 딥러닝 모델이 텍스트와 음성 등 방대한 양의 비정형 원시 데이터를 사용하여 더욱 정확도를 높임으로써 NLP의 지배적인 모드가 되었다.
딥러닝은 신경망 모델을 사용한다는 점에서 통계적 NLP의 더욱 발전된 버전으로 볼 수 있다.
모델은 여러 하위 범주를 갖는다.
2.3.1. 시퀀스-투-시퀀스(seq2seq, Sequence-to-Sequence) 모델
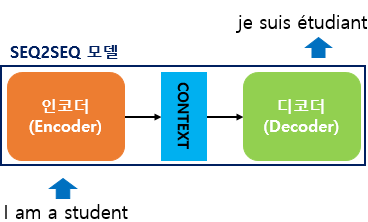
seq2seq 모델
seq2seq 모델: 크게 인코더와 디코더라는 두 개의 모듈로 구성되고, 이 두개의 모듈은 순환 신경망(RNN)을 기반으로 한다.
- 챗봇(Chatbot), 기계 번역(Machine Translation), 내용 요약(Text Summarization), STT(Speech to Text) 등등
2.3.2. 트랜스포머(Transformer) 모델
트랜스포머(Transformer) 모델: 문장 속 단어와 같은 순차 데이터 내의 관계를 추적해 맥락과 의미를 학습하는 신경망 모델이다.
트랜스포머 모델은 요소들 사이의 패턴을 수학적으로 찾아내기 때문에 라벨링 과정이 필요 없다.
- 양방향 인코더 표현 트랜스포머(BERT, Bidirectional Encoder Representations from Transformers) 모델은 Google 검색 엔진 작동 방식의 기반이 되었다.
2.3.3. 자기 회귀(Auto-regressive) 모델
자기 회귀(Auto-regressive) 모델: 시퀀스의 이전 입력에서 측정값을 가져와 시퀀스의 다음 성분을 자동으로 예측하는 기계 학습 모델이다.
자기회귀 LLM은 트랜스포머 모델로 구동되며, 인공지능의 텍스트 생성 능력을 크게 발달시켰다.
2.3.4. 파운데이션(Foundation) 모델
파운데이션(Foundation) 모델: 대량의 원시 데이터, 레이블이 없는 데이터에서 비지도 학습을 통해 훈련된 AI 신경망이다. 파운데이션 모델은 일반적으로 레이블이 없는 데이터세트로 학습해 대규모 컬렉션에서 각각의 항목을 수동으로 분ㄿ하는 데 드는 시간과 비용을 절약할 수 있다.
3. NLP 작업
NLP 작업은 일반적으로 인간의 텍스트와 음성 데이터를 분류하여 컴퓨터가 수집 내용을 쉽게 이해할 수 있도록 한다.
이러한 작업에는 다음이 포함된다.
- 동일 지시성 해결
- 명명된 엔티티 인식
- 품사 태그 지정
- 단어 의미 명확화
3.1. 동일 지시성 해결
동일 지시성 해결(Coreference Resolution): 두 단어가 동일한 엔터티를 지시하는지를 식별한다.
- 특정 대명사가 지칭하는 사람이나 사물을 결정한다.(e.g. ‘그녀’ = ‘헤르미온느’).
- 텍스트에서 은유나 관용구를 식별한다.(e.g. ‘곰’이 동물이 아니라 덩치 크고 털이 많은 사람을 가리키는 경우).
3.2. 명명된 엔티티 인식(NER, Named Entity Recognition)
NER: 단어나 구문을 유용한 엔티티로 식별한다.
- ‘호그와트’ -> 장소
- ‘해리포터’ -> 사람의 이름
3.3. 품사 태그 지정(PoS Tagging, Part-of-Speech Tagging)
Pos Tagging(=문법 태깅): 형태소에 대해 품사를 파악해 부착(tagging)하는 작업이다.
- ‘I can make a paper plane’: ‘make’ -> 동사
- ‘What make of car do you own?’: ‘make’ -> 명사
3.4. 단어 의미 명확화(Word Sense Disambiguation)
단어 의미 명확화(Word Sense Disambiguation): 의미를 여러 개 가진 단어에 대해 적합한 뜻을 선택한다.
- Will, will Will will Will Will’s will?
–> Will, will Will will [to] Will Will’s will?
4. NLP의 작동 방식
NLP는 기계가 처리할 수 있는 방식으로 인간의 언어를 분석, 이해 및 생성하기 위해 다양한 컴퓨팅 기술을 결합하여 작동한다.
4.1. 텍스트 전처리
텍스트 전처리: 원시 텍스트를 기계가 더 쉽게 이해할 수 있는 형식으로 변환하여 분석할 수 있도록 준비한다. 모든 작업은 토큰화에서 시작된다.
- 토큰화: 텍스트를 단어, 문장, 구와 같은 더 작은 단위로 나눈다.
- 소문자 변환: 모든 문자를 소문자로 바꿔서 텍스트를 표준화해 ‘Apple’과 ‘apple’ 같은 단어가 동일하게 처리한다.
- 불용어 제거: ‘is’ 또는 ‘the’같이 자주 사용되지만 텍스트에 큰 의미를 더하지 않는 단어를 필터링하여 제거한다.
- 어간 분석 또는 어근화: ‘달리기’를 ‘달리다’로 바꾸는 것처럼 단어를 어근 형태로 줄이고 동일한 단어의 다양한 형태를 그룹화하여 언어를 더 쉽게 분석할 수 있게 만든다.
- 정규표현: 구두점, 특수 문자, 숫자 등 분석을 복잡하게 만들 수 있는 원치 않는 요소를 제거한다.
전처리가 끝나면 텍스트가 정리되고 표준화되어 머신 러닝 모델이 효과적으로 해석할 수 있게 된다.
4.2. 특징 추출
특징 추출: 원시 텍스트를 기계가 분석하고 해석할 수 있는 수치 표현으로 변환하는 프로세스이다.
- Bag of Words: 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법이다.
- TF-IDF(Term Frequency-Inverse Document Frequency): 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)을 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법이다.
- 워드 임베딩(Word Embedding): 분산 표현(Distributed Representation)을 이용하여 단어 간 의미적 유사성을 벡터화하는 작업이다. e.g. Word2Vec, GloVe 등
- 문장 임베딩: 개별 단어가 아닌 단어 시퀀스 전체의 문맥적 의미를 함축하기 때문에 단어 임베딩보다 효과가 좋다. e.g. BERT, GPT 등
4.3. 텍스트 분석
텍스트 분석: 다양한 계산 기술을 통해 텍스트 데이터에서 의미 있는 정보를 해석하고 추출한다.
- 품사(POS) 태깅: 단어의 문법적 역할을 식별한다.
- 명명된 엔티티 인식(NER): 이름, 위치, 날짜 등의 특정 엔티티를 감지한다.
- 종속성 구문 분석: 단어 간의 문법적 관계를 분석하여 문장 구조를 이해한다.
- 감정 분석: 텍스트의 감정적 어조를 결정하고 텍스트가 긍정적, 부정적 또는 중립적인지 평가한다.
- 주제 모델링: 텍스트 내에서 또는 문서 말뭉치 전체에서 기본 테마 또는 주제를 식별한다.
- 자연어 이해(NLU): 문장의 숨겨진 의미를 분석, NLU를 사용하여 다른 문장에서 유사한 의미를 찾거나 다른 의미를 가진 단어를 처리할 수 있다.
NLP 텍스트 분석은 이러한 기술을 통해 비정형 텍스트를 인사이트로 변환한다.
4.4. 모델 학습
모델 학습: 처리된 데이터를 사용하여 머신 러닝 모델에게 데이터 내의 패턴과 관계를 학습시킨다.
- 학습 중: 모델은 매개 변수를 조정하여 오류를 최소화하고 성능을 개선한다.
- 학습 후: 모델을 사용하여 예측을 수행하거나 보이지 않는 새로운 데이터에 대한 출력을 생성할 수 있다.
NLP 모델링의 효과는 평가, 검증 및 미세 조정을 통해 지속적으로 개선되어 실제 애플리케이션에서 정확성과 관련성을 향상시킨다.
- 자연어 툴킷(NLTK): Python 프로그래밍 언어로 작성된 영어용 라이브러리 및 프로그램 모음이다. 텍스트 분류, 토큰화, 어간 추출, 태깅, 구문 분석 및 의미 추론 기능을 지원한다.
- TensorFlow: 머신 러닝 및 AI를 위한 무료 오픈 소스 소프트웨어 라이브러리로, NLP 애플리케이션용 모델을 학습시키는 데 사용할 수 있다.
5. NLP가 어려운 이유
자연어 처리의 복잡성은 언어 자체의 불완전성, 즉흥성, 다의성, 그리고 비정형적 특성에서 기인한다.
5.1. 자연어의 불완전성
자연어는 시시각각 변화하며 그 자체로 완벽하지 않다.
사람들은 미완성 문장이거나 문법적으로 정확하지 않은 문장이거나, 잘못 발음한다해도 의사소통이라는 본연의 목적을 훌륭하게 달성해낸다.
5.2. 인간 커뮤니케이션의 즉흥성
커뮤니케이션의 즉흥적인 성격은 언어의 다양성을 만들어낸다.
사람이 말을 할 때는 목소리 톤이나 몸짓과 같은 비언어적 표현을 통하여 단어만 사용할 때와 전혀 다른 의미를 전달할 수 있다.
5.3. 언어의 다의성과 문맥의 중요성
언어의 다의성이란 하나의 단어나 문장이 상황에 따라 여러 가지 의미를 가질 수 있다는 것이다.
예를 들어 “배”라는 단어는 과일의 이름일 수도 있고, 배를 타고 가는 행위를 의미할 수도 있다.
5.4. 비표준적 표현과 비정형 데이터
인터넷과 SNS의 보급으로 비표준적 언어 사용이 일반화되고 있다.
사투리, 속어, 관용구, 줄임말, 이모티콘, 신조어 등은 비정형 데이터의 형태로 나타나며, 이는 전통적인 언어 규칙을 따르지 않는다.
출처
- 자연어 처리(NLP)란 무엇인가요?
- 머신러닝이란?
- 컴퓨터언어학이란
- [자연어처리] 6.구문 분석
- [기초통계] 확률(Probability) vs 우도(가능도,Likelihood)
- 확률과 우도 그리고 확률 밀도 함수
- 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)
- 트랜스포머 모델이란 무엇인가? (1)
- 마르코프 속성: 분석에서 마르코프 속성의 힘 활용
- 마르코프 모델 - 마르코프 체인 (Markov models)
- 자기 회귀 모델이란 무엇인가요?
- 파운데이션 모델이란 무엇인가?
- 품사 태깅(Part-of-Speech Tagging)이란?
- Bag of Words(BoW)
- TF-IDF(Term Frequency-Inverse Document Frequency)
- 워드투벡터(Word2Vec)
- 임베딩(Embedding)이란?
- 자연어 처리(NLP)는 왜 어려울까?
Comments