한글 텍스트 자연어 처리 실습 1
목차
1. 활용 데이터셋 소개
소설 「해리 포터」 시리즈

2. 환경설정 (Google Colab)
2.1. 환경설정 진행
!pip install mecab-ko-dic
!curl -s https://raw.githubusercontent.com/teddylee777/machine-learning/master/99-Misc/01-Colab/mecab-colab.sh | bash
!pip install konlpy # KoNLPy: Korean NLP in Python
!pip install kss # KSS: Korean String processing Suite
2.2. 라이브러리 import
# import module
import re # regular expression module
from IPython.display import display
from typing import * # python type hint module
from time import time
from random import randint
import os
from konlpy.tag import Okt, Mecab, Komoran, Hannanum, Kkma # word tokenization module
from mecab import MeCab
import mecab_ko_dic
import kss # sentence tokenization module
import torch
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import numpy as np
from tqdm import tqdm, tqdm_notebook
import pandas as pd
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
from future.utils import iteritems
from collections import Counter
from sklearn.manifold import TSNE
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
2.3. 해리포터 불러오기
import os
def file_search(file_path: str):
file_lst:List[str] = []
files:List[str] = os.listdir(file_path)
try:
for file in files:
file_full_path = os.path.join(file_path, file)
if os.path.isdir(file_full_path):
file_search(file_full_path)
else:
file_lst.append(file_full_path)
except PermissionError:
pass
return file_lst
# Read Korean Text Data Set
file_path:str = "/content"
file_lst:List[str] = sorted(file_search(file_path))

우선 해리포터 1권, 「해리 포터와 마법사의 돌」로 시작하겠습니다.
with open(file_lst[0], "r", encoding='utf-8') as f:
texts = f.read()

2.4. 데이터 전처리하기
목차 삭제 및 문장 단위 토큰화
import re # regular expression module
import kss # sentence tokenization module
# '제1장 버려진 아이' 같은 목차 삭제
texts = re.sub(r'제\s*\d+\s*장\s*[^\n]*\n?', '', texts)
# korean sentence tokenization -> 문장 기준 토큰화
texts:List[str] = kss.split_sentences(texts)

챕터별로 나눌까?
형태소 단위 토큰화
from typing import * # python type hint module
import re # regular expression module
from konlpy.tag import Okt, Mecab, Komoran, Hannanum, Kkma # word tokenization module
from mecab import MeCab
import mecab_ko_dic
def tokenizer(module:object, texts:List[str]) -> Dict[Any, Any]:
tokens:List[str] = [] # 형태소 단위 token
tokenized_texts:List[str] = []
max_seq_length:int = 0
exec_time:float = 0
start_time:float = time()
for text in texts:
tokenized_text:List[str] = module.morphs(text) # 형태소 단위 token 추출
for token in tokenized_text:
if token.strip() and not re.match(r'[^a-zA-Z0-9가-힣\s]', token.strip()): # 공백 문자, 특수 문자로만 구성된 token은 제거
tokens.append(token)
max_seq_length = max(max_seq_length, len(tokenized_text)) # sequence(형태소 단위로 구분된 문장) 최대 길이
# sequence: 순서가 있는 항목의 모음, 순차 데이터
tokenized_text:str = " ".join(tokenized_text)
tokenized_texts.append(tokenized_text)
end_time:float = time()
exec_time = end_time - start_time
res:Dict = {'tokens': tokens,
'tokenized_texts': tokenized_texts,
'max_seq_length': max_seq_length,
'exec_time': exec_time}
return res
KoNLPy 형태소 분석 비교
from konlpy.tag import Okt, Mecab, Komoran, Hannanum, Kkma # word tokenization module
from mecab import MeCab
import mecab_ko_dic
okt = Okt()
tokenizer(okt, texts)
kkma = Kkma()
tokenizer(kkma, texts)
mecab = MeCab()
tokenizer(mecab, texts)
komoran = Komoran()
tokenizer(komoran, texts)
hannanum = Hannanum()
tokenizer(hannanum, texts)
import matplotlib.pyplot as plt
# 각 KoNLPy의 형태소 분석 시간 분석 -> 막대 그래프
exec_tool:List[str] = ['okt', 'kkma', 'mecab', 'komoran', 'hannanum']
exec_time_lst:List[float] = [okt_res['exec_time'], kkma_res['exec_time'],
mecab_res['exec_time'], komoran_res['exec_time'],
hannanum_res['exec_time'],]
bar_colors = ['red', 'orange', 'yellow', 'green', 'blue']
fig, ax = plt.subplots()
bar = ax.bar(exec_tool, exec_time_lst, color=bar_colors)
for rect in bar:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width()/2, height, f'%0.1f'%height, ha='center', va='bottom', size=12)
ax.set_ylabel('time(sec)')
ax.set_title('execution time')
plt.show()
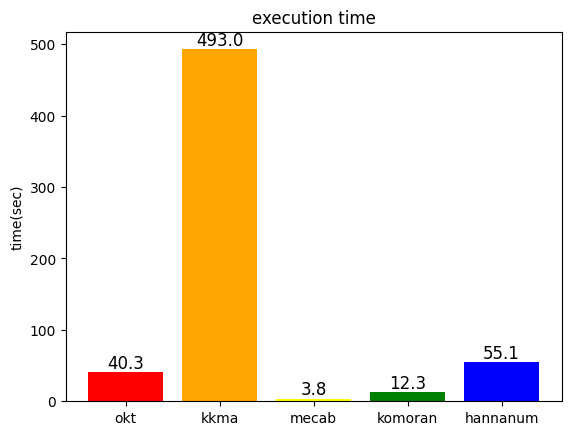 -> mecab의 속도가 압도적으로 빠르다
-> mecab의 속도가 압도적으로 빠르다
mecab의 형태소 분석 결과 중 일부이다.
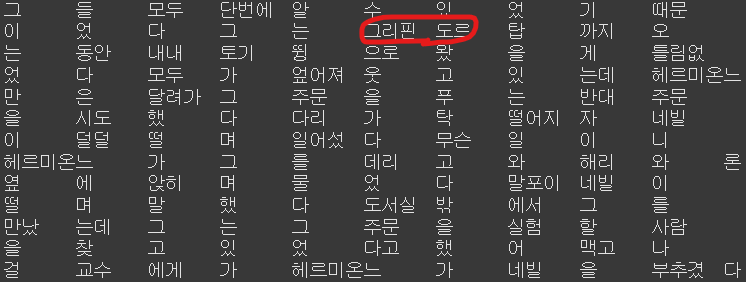 -> 이름과 같은 고유 명사가 분리되어 있는 경우를 몇몇 발견했다. e.g. 프리벳가, 더즐리, 덤블도어, 해그리드, 그리핀도르 등
-> 이름과 같은 고유 명사가 분리되어 있는 경우를 몇몇 발견했다. e.g. 프리벳가, 더즐리, 덤블도어, 해그리드, 그리핀도르 등
-> 이러한 고유 명사들은 mecab의 user-dictionary에 추가할 예정이다.
2.5. 문서 벡터
TF-IDF
import pandas as pd
from collections import Counter
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
tf = CountVectorizer()
# 코퍼스로부터 각 단어의 빈도수를 기록
tf.fit_transform(texts).toarray()
# 각 단어와 맵핑된 인덱스 출력
tf.vocabulary_
tfidf = TfidfVectorizer().fit(texts)
tfidf_arr = tfidf.transform(texts).toarray()
tfidf_dict = tfidf.get_feature_names_out()
tfidf_df = pd.DataFrame(tfidf_arr, columns=tfidf_dict)
tfidf_vocab = tfidf.vocabulary_

차원 축소
from sklearn.manifold import TSNE
# 차원 축소
tsne = TSNE(n_components=2, n_iter=10000, verbose=1)
Z = tsne.fit_transform(tfidf_arr.T)
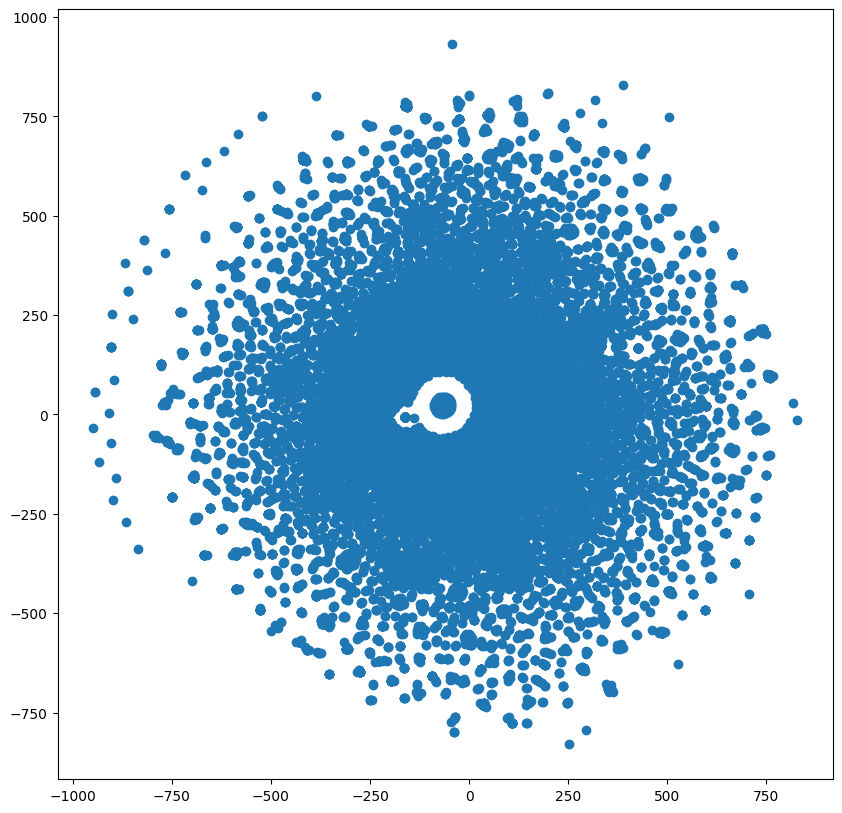
시각화
plt.figure(figsize=(10,10))
plt.scatter(Z[:,0], Z[:,1])
center = []
for i in range(len(tfidf_dict)):
if -100 < Z[i,0] < 100 and -100 < Z[i,1] < 100:
plt.annotate('', xy=(Z[i,0], Z[i,1]), c='red')
center.append(tfidf_dict[i])
else:
plt.annotate('', xy=(Z[i,0], Z[i,1]))
plt.draw()
참고
Information
- KoBERT를 활용한 감정분류 모델 구현 with Colab
- 감정분류(한국어)- 리뷰데이터 학습, 평가, 예측까지
- 텍스트 정보 추출 모델 (with. 개체명 인식(NER))
- 파이썬 KoBERT 패키지 설치 및 onnxruntime 설치오류
- session Crashing: while installing python version 3.7 and transformers version 4.6.0 in Google Colab
- KoNLPY - okt 사용자 사전 편집 방법
- 자연어 분석의 4단계 및 기계학습에의 적용 방식
- [Python, KoBERT] 7가지 감정의 다중감성분류모델 구현하기
- 형태소 분석기 정리, 사용자 사전 추가 feat. Pororo, Okt, Mecab, Soynlp, Kiwi
- TF-IDF를 통한 변수선택과 t-SNE를 활용한 시각화
- 시각화: t-SNE (t-Stochastic Neighbor Embedding)
- t-SNE란? (차원축소, 시각화)
- youtube: 2021 자연어 처리 - NER
- 속성기반 감정분석 데이터, AI HUB
- Installing previous versions of PyTorch
- python-mecab-ko: Dictionary
- python-mecab-ko: Custom Vocabulary
- KoNLPy tag Package
- 텍스트 전처리(Text preprocessing)
- 정규표현식(Regular Expression) with 파이썬
- BERT를 이용한 한국어 개체명 인식(NER)
- NER task for Naver NLP Challenge 2018 (3rd Place)
- plt 선, 바 그래프 위에 숫자, 값 표시하기
- 형태소 분석기의 모호성 해소 성능을 평가해보자
- 보편적으로 선택할 수 있는 한국어 불용어 리스트
- 한글 품사 태깅에 대한 세 가지 접근 방법
- 한국어/영어 불용어 제거하기 + 한국어 불용어 리스트
- 정수 인코딩(Integer Encoding)
- 품사 태깅(Part-of-Speech Tagging)이란?
- t-SNE 이란?
- t-SNE 개념과 사용법
- Module kiwipiepy
- [NLP] 자연어처리 - 한국어 전처리를 위한 기법들
- 한국어 위키피디아로 Word2Vec 학습하기
- 나무위키: 해리포터 등장인물
- 품사표 (PoS Table)
- 전이학습(Transfer learning)과 파인튜닝(Fine tuning)
Github
- KoBookNLP
- KoBERT
- KoBERT-Transformers
- Korean NER based BERT+CRF
- 개체명 형태소 말뭉치
- NER Model Baseline for NSML
- Naver Sentiment Movie Corpus v1.0
- KoSentenceBERT-SKT
- HiGRU - Hierarchical Gated Recurrent Units for Utterance-level Emotion Recognition
- A 사전 모델 학습: 한국어 감정 정보가 포함된 단발성 대화 데이터셋.py
- Fine tuning BERT
- KorNLI and KorSTS
- okt
- mecab
- 언어모델 기반 개체명 인식 기술을 활용한 119 신고 접수 도움 서비스
Comments